Hello, fellow data enthusiasts!
Are you ready to dive into the world of Retrieval Augmented Generation (RAG)? Buckle up because we’re about to start a journey through one of the coolest advancements in machine learning. And don’t worry, I promise to keep the tech details to a minimum – we’re all about having a bit of fun here!😀
What’s RAG?
According to IBM, ‘Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the Large Language Model’s internal representation of information.’
Easy right?
I’m kidding😅 Let’s talk English please!
Imagine you’re designing a personal stylist app, yes exactly like Style DNA, you load it with all those screenshots you took for your favorite celebrity, every fashion magazine, instagram post, … Next you ask it to create a trendy outfit for your birthday celebration party. Traditional machine learning models will simply combine a topwear with that classic black pant (Cliché I know!), or your black suit with the orange tie🤦 But with Retrieval Augmented Generation (RAG), it’s like giving your app the power to scan all those fashion resources, identify latest trends and then assemble an outfit that’s not only perfect to welcome the new year but also on the cutting edge of fashion.🤩
In technical terms, RAG is a methodology in machine learning where a model first retrieves information from a large dataset and then generates new content based on that information. Remember, Retrieve and Generate.
Why Is RAG So Cool?
- RAG models can pull in information from vast data sources to make sure what they generate is not just smart-sounding, but actually smart.
- RAG Models do cross-checking with existing data and thus, tend to make fewer “oopsies”🤦 in their outputs.
- RAG Models are Versatile: From writing essays to helping diagnose diseases, they have a wide range of applications. They’re like the Swiss Army knife of machine learning. ☮️
RAG in Action – Not Just Sci-Fi!
Think of a chatbot. Now, make it ten times smarter. That’s a RAG-augmented chatbot for you. It doesn’t just respond with pre-fed answers; it can pull in information from all over the place to give you a response that’s more informative than “I’m sorry, I didn’t get that.”
Or wait a minute.. Who’s not obsessed with content creation nowadays? A RAG model can help generate articles (like this one, perhaps?) by retrieving relevant information and then synthesizing it into something new and exciting – and not just a rehashed Wikipedia page.
Now it’s Tech Time
Remember when I said it’s all about retrieving and generating? Now it’s time to explain this further.
Simply speaking, RAG works by combining two main technical components: a retrieval system and a generative model. Let’s see how typically it functions on the technical level.
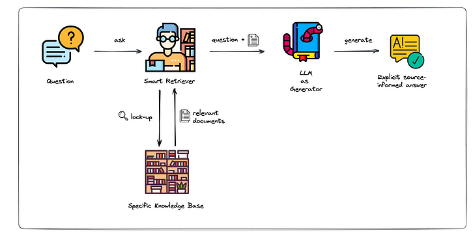
- The retriever: When a query or a question is posed, the retrieval system searches through a large database of documents or a knowledge base to find relevant information. This mainly relies on the similarity measure (like cosine similarity) between the query and the documents. So this phase is more like The Sherlock Holmes of Data but the model lacks the ability to generate creative or novel content. Stick to the fact, just the fact!😠
- The generator: Now, hold onto your hats because once the retriever has fetched the good stuff, it’s showtime for the generator! The model takes into account both the input query and the context provided by the retrieved documents to prepare responses that have the flair of a novelist and the precision of an encyclopedia!
The generative model integrates the retrieved information by conditioning its responses on the context. This ensures that the generated text is not just based on the patterns learned during its training but is also informed by specific data relevant to the query.
Curious to see what’s behind the colored icons in the previous image?
Tada!
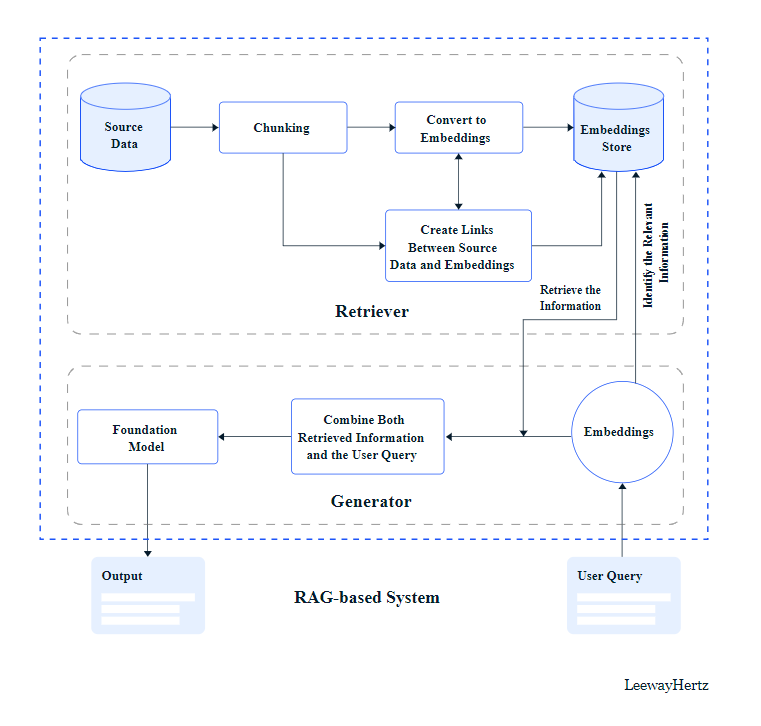
Upon receiving your query, a complex process, obviously😄, starts at the foundation of our RAG-based system where the query is first segmented into digestible pieces that are then encoded into rich embeddings (a fancy way to say numerical vectors). This step is crucial so that the machine can search for semantically similar items based on the numerical representation of the stored data.
I can only read numbers
In the heart of the operation, the Retriever acts with precision, pinpointing the embeddings that align with your query. This game of matching is key to sourcing the most relevant information.
With the intelligence gathered, the Generator takes over. It integrates the context from the Retriever with your initial inquiry, crafting a precise response. In other words, the system brings together the identified data chunks and your original prompt, laying the groundwork for the foundation model, like GPT (Generative Pretrained Transformer), to step in.
The outcome is a seamless blend of retrieved knowledge and generative expertise, culminating in an output that is both insightful and relevant to your query. This is the essence of RAG: a system where complexity meets clarity, transforming how we interact with and benefit from AI in our quest for information.
But Wait, There’s a Catch!
Before you start thinking RAG models are the solution to all life’s problems, remember – they’re only as good as the data they have access to.
🚮 in, 🚮 out, as they say. You know what I’m talking about, right?