Output Quality: The model works well, but its output depends on the quality of the training data. During testing, we found that while the voice was clear, some Arabic pronunciations could be improved.
Real-Time Use: Although Coqui-XTTS aims to generate speech quickly, it still needs some work to reduce delays. We are looking into ways to make the process faster for better user experience.
It’s important to note that these two models are not directly comparable at this stage. The RVC model sounds better, mainly because it is trained on the target voice itself. In contrast, the Coqui model is fine-tuned for the Arabic language and may sound more robotic due to the difference in training data.
Limitations faced
- Real-Time Performance for coqui model: Achieving real-time voice cloning was difficult due to processing delays, which slowed down application response.
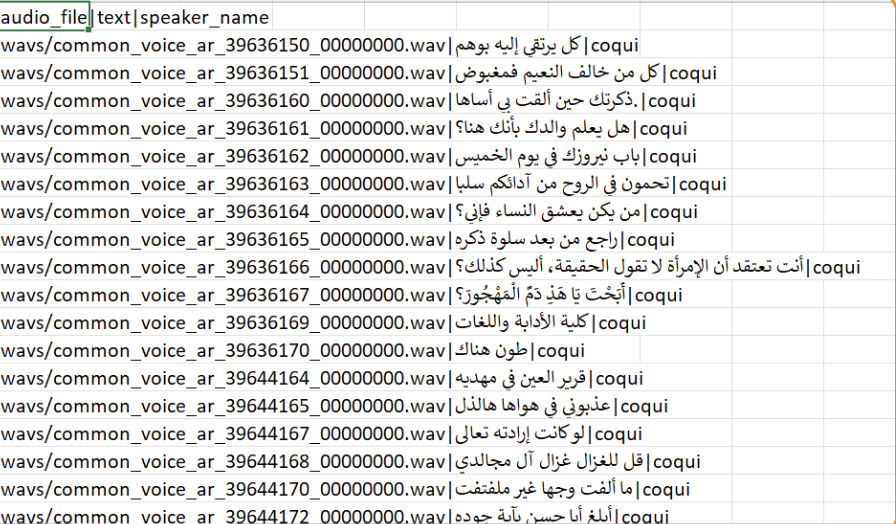
- Lack of Good Arabic Data: There wasn’t enough good Arabic speech data, making it tough for the model to learn effectively.
- Voice Naturalness: The Coqui XTTS model sometimes sounded robotic and didn’t produce the natural-sounding speech we wanted.
- Accent and Pronunciation in RVC: The RVC model only works well with the accents and pronunciations it was trained on, so it may not produce accurate results for other Arabic dialects.
- Limited GPU Resources: We had limited GPU resources, especially in Google Colab, which restricted our ability to improve the model or do more training.
Deployment Phase
Deployment Phase
In our deployment, we used the Gradio interface for its simplicity and user-friendliness, making it suitable for real-time interaction. We divided our interface into tabs, each with different functionalities. The first tab is for RVC inference, the second tab allows users to upload their trained RVC model using the W-okada software and test it in real time, and the last tab is for Coqui XTTS model inference.
Once the web UI is launched, to infer RVC specify the model and input the audio file , then press the conversion button. Then you choose one of the pitch extraction algorithms according to your preference, you can use them as follows::
PM: Best for speed. Use it when you need fast processing and real-time performance but can compromise a bit on accuracy.
Crepe:Best for high accuracy. Use this when you want the most accurate pitch detection, even if the audio is noisy or complex, but don’t mind slower performance.
RMVPE:Best for real-time applications. Use this when you need a good balance between speed and accuracy, especially for real-time voice processing.
Harvest:Best for smooth, natural-sounding output. Use this when you want high-quality and natural pitch results, even if it takes a bit longer to process.