Fine Tuning Image Generation Models that see the Arab World Accurately.
Text-to-image AI models like Stable Diffusion, Midjourney, and DALL·E have redefined what’s possible in the creative generation. Yet while they can produce breathtaking visuals from simple prompts, their general-purpose training often falls short when users need specific styles, faces, concepts, or languages.
The solution? Fine-tuning. By adapting pretrained models to domain-specific data, we unlock personalization, improve prompt alignment, and inject cultural or stylistic nuance. For example, we can fine tune a model to learn the cultural nuances and face features aligned with our Arab region, to deliver image generation that feels more natural.
In this blog, we explore the main techniques for fine-tuning image generation models, compare fine tuning methods, and walk through the key steps for building your own tuned model.
Why Fine-Tune?
Pretrained diffusion models like Stable Diffusion are trained on billions of image-text pairs, mostly scraped from the internet. While powerful, they can be:
• Generic: Missing niche or custom domains (e.g., specific characters, brands, cultural content).
• Unreliable with new styles: Struggle to match very specific aesthetics.
• Biased: Overrepresent some geographies, faces, or themes.
Fine-tuning lets us steer the model more precisely, enabling it to generate:
• Custom characters or identities
• Brand-consistent visuals
• Domain or culture specific concepts
Overview of Fine-Tuning Strategies
🟠 Full Fine-Tuning
Retraining the entire model (UNet, VAE, and text encoder) on new data.
Pros:
• Maximum adaptability
• Can shift the model deeply toward new concepts
Cons:
• Requires massive computing (multiple GPUs, days of training)
• High risk of overfitting or catastrophic forgetting
• Not scalable for multiple concepts
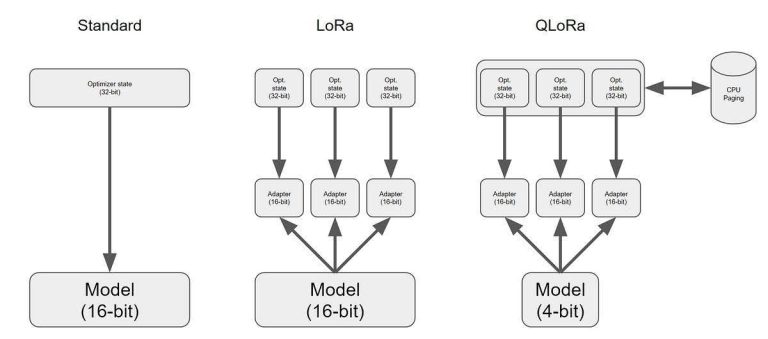
🟠 LoRA (Low-Rank Adaptation)
A lightweight method that inserts trainable adapter modules into attention layers of the model (e.g., UNet or text encoder).
How it works:
• Keeps the original model frozen.
• Trains small matrix deltas (“LoRA weights”) that are later merged or applied at inference.
Pros:
• Requires much less computing
• Can train on a single GPU
• Modular: multiple LoRAs can be swapped or merged
• Works well for style tuning, domain adaptation, or concept injection
Cons:
• Limited by the base model’s learned features
• Might underperform in extreme domain shifts vs. full tuning
🟠 QLoRA (Quantized LoRA)
QLoRA takes the efficiency of LoRA even further by enabling training on quantized models, typically 4-bit versions, without compromising much on performance.
How it works:
• Quantizes the base model to 4-bit using double quantization.
• Keeps the backbone model frozen and trains LoRA adapters on top.
• Uses memory-efficient optimizers (paged optimizers like PagedAdamW).
Why it matters for image generation:
• While originally designed for large language models, QLoRA is increasingly relevant for multimodal models where memory is a constraint.
• It allows fine-tuning of larger base models on consumer-grade hardware.
Pros:
• Massive memory savings, enables training on GPUs with <24GB VRAM.
• Minimal performance drop compared to full-precision LoRA.
• Enables experimentation with much larger backbones.
Cons:
• Still experimental in many diffusion-based workflows.
• Debugging and inference can be trickier due to quantization.
🟠Dataset Quality and Captioning Regardless of method, data quality is king.
Images should be high-resolution, visually consistent, and relevant.
Captions should be concise, accurate, and visually grounded (not poetic or abstract).
🟠Preprocessing and Training Essentials Before training:
• Normalize image sizes (e.g., 512×512 or 768×768)
• Convert all images to a standard format (PNG or JPEG, 8-bit)
• Tokenize captions using the base model’s tokenizer
Optional Enhancements:
• Data augmentation: Rotate, crop, jitter colors to boost generalization
• Balanced sampling: If some classes are overrepresented, use weighted sampling
Case Study: Culturally Aware Image Generation for the Arab World
A common challenge with popular online image generation models is that they are rarely trained on Arabic data.
Their datasets are overwhelmingly skewed toward Western or East Asian cultures, which means they often fail to capture the details of Arab clothing, people, environments, or architecture. This cultural gap can lead to inaccurate or generic outputs when generating content related to the Arab world.
Here are some concrete examples of the biases and stereotypes of such models:
Prompt: Arab scientist in a lab
Generated images:
As seen in the example above, the prompt “Arab scientist in a lab” returns images of a man wearing a keffiyeh, which is a traditional Gulf garment. While culturally significant, they are not appropriate attire for a laboratory setting. This highlights how general models often associate the term “Arab” with a limited and stereotypical visual representation.
Prompt: Portrait of a professional Emirati woman
Generate images:
In this example, the prompt “professional Emirati woman“ generates an image of a woman wearing a keffiyeh and an abaya. While the abaya is culturally appropriate, the keffiyeh is traditionally male attire. Moreover, the setting lacks any indicators of a professional environment. Instead of portraying a woman in a workplace or business attire, the model defaults to vague or mismatched cultural symbols, revealing a limited understanding of both gender roles and professional contexts in the region.
To address this, MadeBy partnered with the MiddleFrame to create the first image generation model designed for the Arab world.
The Goal: To improve how generative models depict Arab people, architecture, attire, and settings. Areas where mainstream models often show gaps or inaccuracies.
What We Did:
We curated a dataset of over one million images representing diverse Arab regions, but we are taking a phased approach. Starting with a focused subset of 14,000 images and 60,000 face-centric samples to closely monitor results and guide iterative fine-tuning.
Focused on detailed, visually grounded captions (~5–20 words)
Preprocessed all images to 512×512 resolution, standardized formats, and tokenized all text for training.
Fine-tuned models using LoRA adapters for efficient training, keeping the backbone frozen.
Ran controlled experiments on multiple base models including Stable Diffusion XL, 3.5, and Flux, evaluating prompt alignment and cultural accuracy.
Here are some samples of the results on the same prompts:
Prompt: A woman in modest traditional clothing leaning against the sunlit stone wall of an old house, with carved wooden windows and climbing jasmine vines
Prompt: A traditional Arabic wedding scene outdoors with draped fabrics, colorful garments, and guests clapping to drum music
Prompt: Egyptian man in Moez street wearing traditional clothing
Customization is the Future
As generative AI continues to evolve, the ability to customize and align models to specific identities, cultures, and aesthetics is becoming essential, not optional. Fine-tuning isn’t just about making better art. It’s about making relevant, inclusive, and context-aware content.
Whether you’re trying to localize imagery, capture a new visual language, or run a powerful model on limited hardware, techniques like LoRA and QLoRA make fine-tuning accessible, efficient, and scalable.