Most people misunderstand how AI works. This simple explanation reveals the common misconceptions and shows how large language models actually generate text by predicting the next word based on patterns.
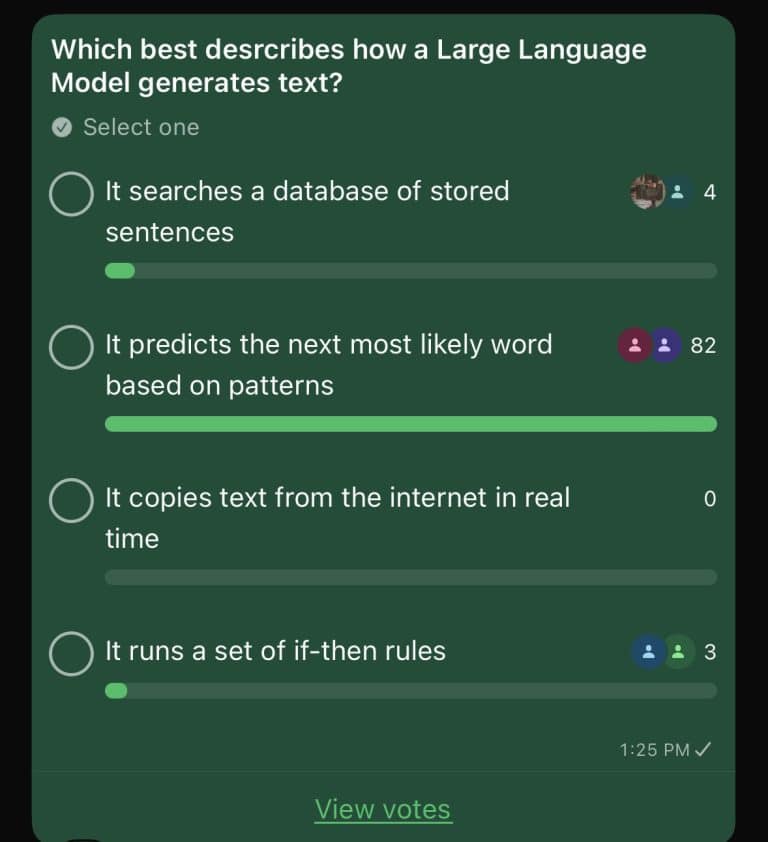
We asked our community a simple question: “Which best describes how a Large Language Model generates text?”
Four options. One right answer. Most people did not pick it.
And the ones who got it wrong did not get it wrong because they are not smart. They got it wrong because nobody ever actually explained what is happening inside these tools they use every day. That is worth fixing.
The wrong answers tell the right story
Before getting to what is correct, it is worth understanding why the wrong answers feel so convincing. Each one is a reasonable inference from real experience.
Wrong
It searches a database of stored sentences
You ask ChatGPT something and it responds instantly with a perfectly structured answer.
Must be pulling from somewhere, right? Like a very advanced copy-paste. The intuition is understandable.
But there is no library of pre-written sentences being retrieved. Nothing is being looked up and handed back to you.
Wrong
It copies text from the internet in real time
Also intuitive. It knows so much. It sounds so current. It must be browsing, reading,
and repeating. But a standard LLM is not connected to the internet during your conversation.
It is not reading anything in real time. What it knows, it learned before you ever opened the chat.
Wrong
It runs a set of if-then rules
This one comes from a reasonable model of how software works. Code is logic. Logic is rules.
So AI must be a very complex set of rules. But there are no rules written by a human deciding what the AI says next.
No decision tree. Something far stranger and more interesting is happening.
THE CORRECT ANSWER
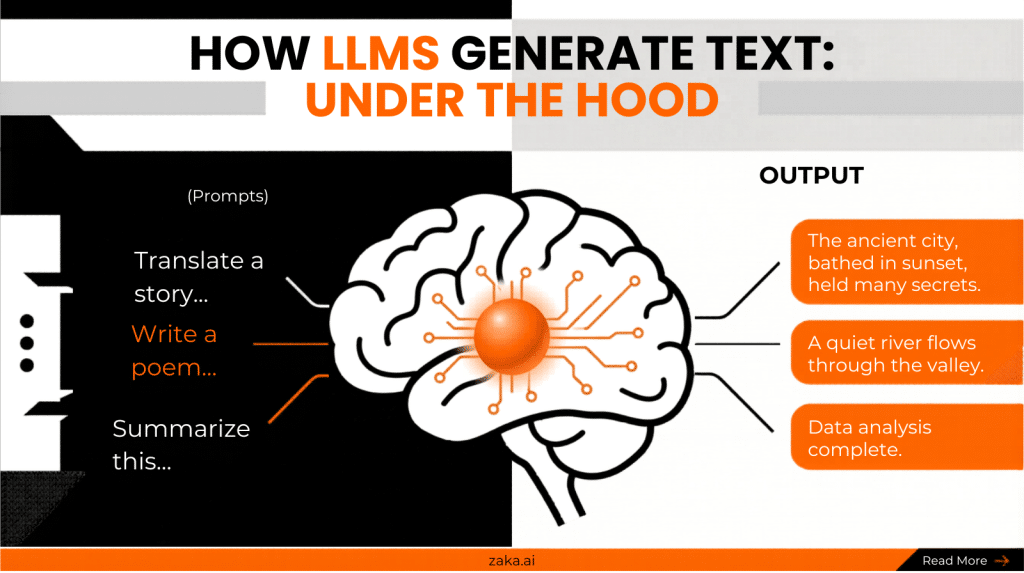
It predicts the next most likely word based on patterns.
Not searching. Not copying. Not following rules. Predicting one token at a time, informed by everything that came before.
What prediction actually means
Here is where most explanations lose people. They say “predicts the next word” and leave it there, as if that phrase explains anything. It does not. So let’s go deeper.
An LLM was trained on an enormous amount of text books, articles, websites, conversations. During that training, it did one thing billions of times over: it looked at a sequence of words and learned to predict what word would come next.
It did not memorize. It recognized patterns the shape of language itself.
So when you type a message, it does not look anything up. It takes your words as a starting point and begins predicting one token at a time what a coherent, relevant continuation looks like. Then it predicts the next one. And the next. And the next.
That entire response you receive? Generated one word at a time, each one informed by everything that came before it.
How the training actually works
LLM Process Section
01
Exposure to vast text
The model reads enormous volumes of written language billions of
sentences across every conceivable topic and style. Not to store them,
but to absorb the patterns within them.
02
Learning to predict
Over and over, it is shown the beginning of a sentence and asked what
comes next. It guesses. It is corrected. It adjusts. Millions of times,
until its guesses become remarkably good.
03
Weights, not words
What the model ends up with is not a database of text. It is billions
of numerical weights a compressed representation of statistical
relationships in language. That is what gets deployed when you open a
chat.
04
Generation, not retrieval
When you send a message, those weights activate. The model generates a
response token by token, each prediction shaped by your input and every
token it has produced so far. It is creating, not fetching.
Why this misunderstanding actually matters
This is not just trivia. The mental model you bring to AI changes how you use it and how much you get out of it.
If you think it searches a database, you treat it like a search engine. Short queries. Factual lookups. Frustration when it gets things wrong, because databases do not make things up.
If you think it copies from the internet, you distrust it by default and miss what it is actually capable of creating from scratch.
If you think it follows rules, you assume it is rigid. You do not push it to reason, reframe, or generate something genuinely new.
But if you understand it is predicting pattern-matching at a scale the human brain cannot replicate something shifts. You stop asking it to retrieve and start asking it to think.
Ready to build your first agent?
Schedule a call with our team and we will help you map exactly where to start.