Step into the Scene: Replacing Celebrities with You through AI Magic
“The Interactive Room” is a groundbreaking project that was developed by ZAKA’s talented AI Certification students, Abbas Naim and Razan Dakak, in collaboration with the AI Development team at ZAKA “MadeBy“. The AI team is focused on providing cutting-edge AI solutions to our clients, and this initiative showcases our capabilities in integrating state-of-the-art AI models to create innovative, personalized experiences. Stay tuned as we continue to push the boundaries of AI in innovation, education, and beyond
Imagine being able to place yourself in iconic movie scenes, swapping faces with your favorite celebrities, and even syncing your voice with their lines. Sounds like a dream? Well, it’s now a reality with the Interactive Room project. By combining advanced technologies like gender classification, deepfake face swapping, and voice synthesis, we have created a platform that lets users experience movies in a way never imagined before.
This blog takes you through the technical development of the project, the challenges we faced, and the solutions we implemented to bring this unique experience to life.
With the growing demand for personalized content and immersive experiences, many projects have tried to blend users into digital content. However, most solutions face three key challenges:
Accurate gender classification to tailor the facial swap process.
High-quality face swaps that maintain natural expressions, especially in dynamic scenes.
Realistic voice synthesis to match the user’s voice with the original audio.
Previous attempts using older deepfake models and generic text-to-speech (TTS) systems either lacked quality or struggled with real-time processing. Our approach leverages state-of-the-art AI models to address these challenges and create a seamless experience for users.
AI models in action
1. Gender Classification – The First Step in the Pipeline
The first step in the Interactive Room pipeline is to detect the user’s gender based on the uploaded image. This classification step helps tailor the face-swapping process by optimizing for gender-specific features.
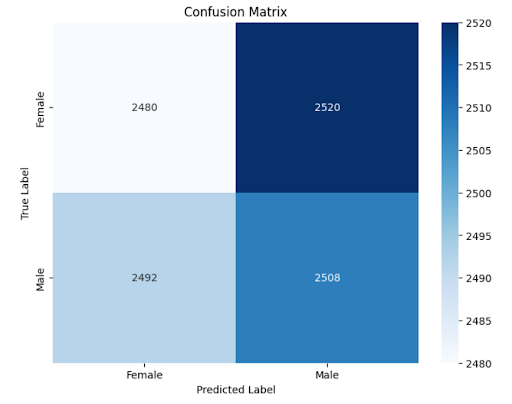
VGG16 & InceptionV3: Initially, we experimented with VGG16 and InceptionV3 due to their reputation in image classification. However, these models underperformed in terms of precision and accuracy on our dataset.
YOLOv8: Moving towards YOLO-based models, we tested YOLOv8, which yielded better results but still did not meet our expectations.
YOLOv10: Finally, we chose YOLOv10 as it offered a strong balance of accuracy and speed. We used pretrained weights for YOLOv10, which streamlined the process, reducing training time significantly while delivering robust classification results.
Why YOLOv10?
Improved Accuracy: YOLOv10 delivered high accuracy in gender detection.
Speed: The model processed data quickly, which was essential for efficient face-swapping in the next stages.
Pretrained Weights: Leveraging pretrained weights saved both time and computational resources, providing accurate results with minimal retraining.
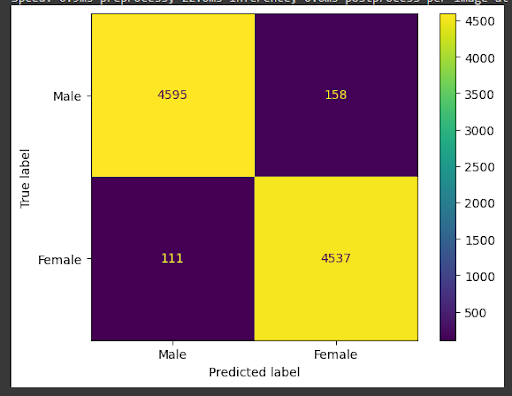
Below is the confusion matrix compared between VGG16 and Yolov10s. The first one is for the Yolo model.
2. Face Swapping – Blending Users into Their Favorite Scenes
Once the gender is classified, the image, along with the chosen movie or TV scene, is passed through the pipeline to perform deepfake face swapping.
Roop: We started with Roop to get a feel for how face-swapping models work. Roop helped us understand the basic mechanics but didn’t achieve the realism required for our project.
SimSwap: We switched to SimSwap, which generated much more realistic face swaps. It handled multiple faces in a scene, preserved facial expressions better, and offered a more natural final result.
As a comparison between Roop and SimSwap, we can see the following result of the original scene below:
SimSwap Result
Roop Result
Why SimSwap?
Higher Swap Quality: SimSwap produced seamless and natural-looking face swaps.
Expression Retention: The model retained subtle facial expressions, which enhanced the realism of the swapped face as seen in the picture.
Optimized for Multiple Faces: SimSwap worked well even in scenes with multiple characters, ensuring that the user’s face blended in naturally with the environment.
Short period: if the video is less than 1 minute, it does not take more than 12 minutes using SimSwap, while for Roop it takes almost 40 minutes.
Trainable: as suggested in SimSwap guidance, we need to train it for an average of 400K steps, we did train it for 390K and the results are as shown.
The image below shows how one face is swapped in place of the famous actress scene Maguy Bou Ghoson in Julia Series.
3. Voice Synthesis – Converting the User’s Voice to Match the Scene
The final step of the pipeline is voice synthesis, where we provide two options: users can either record their voice or use the extracted original audio from the scene. For the recorded voice, we use a text-to-speech (TTS) model to convert the user’s input into a voice that blends with the scene’s original audio.
OpenVoice (Shell.ai): Initially, we tested OpenVoice, but its synthesis time was too long for real-time application.
Tacotron: We explored Tacotron for voice synthesis, which provided decent results, but fell short in terms of naturalness.
Coqui xTTS: Ultimately, we selected Coqui xTTS for its ability to generate natural, high-quality voices quickly. It handled various accents and languages, making it the best fit for our project.
Why Coqui xTTS?
High-Quality Voice Output: Coqui xTTS consistently produced the most natural and lifelike voice conversions.
Fast Synthesis: The model’s quick synthesis time made it suitable for real-time interaction with users.
Versatility in Accents and Languages: Coqui xTTS excelled in handling different languages and accents, which allowed us to personalize the voice output according to the user’s preferences.
Once the voice is synthesized, it can be blended into the original audio from the video, completing the scene substitution.
Setting up procedure
To create a seamless pipeline for users, we integrated the following components:
Data Collection: We collected various movie scenes featuring male and female actors to create a robust dataset for testing both face-swapping and voice synthesis. We also collected datasets of both genders for training our gender model.
Training Environment: The gender classification model was trained using google colab which worked fine, we optimized it for our dataset, achieving over 95% accuracy in detecting gender. While the SimSwap model was trained using Atlas.ai’s GPU resources, enabling faster experimentation and tuning since we wanted to achieve the best results it was recommended to train it up to 400K steps.
Face Swapping: We tested different scenes using SimSwap and fine-tuned the model to handle various lighting conditions, backgrounds, and multiple characters.
Voice Synthesis: Coqui xTTS was integrated into the pipeline to provide real-time voice synthesis, with customization options for accent and tone.
Results and Findings
Gender Classification: YOLOv10 delivered over 95% accuracy, outperforming earlier models like VGG16 and InceptionV3. The real-time detection speed ensured minimal lag for users.
Face Swapping: SimSwap successfully handled scenes with multiple faces and preserved subtle expressions. Users reported a high level of satisfaction with the swap’s realism, and the model showed impressive generalization across different scenes.
Voice Synthesis: Coqui xTTS achieved near-instantaneous voice generation with high-quality, natural-sounding outputs. Users appreciated the system’s ability to adapt voices to different accents, improving the immersion of the overall experience.
The results of this project, with voice cloning can be seen here for both genders.
Project results
2 Videos
0:16
0:16
User Interface (UI)
For the user interface, we chose Gradio to provide an easy-to-use platform where users can upload their images, select scenes, and record their voices. Gradio allowed us to focus on building an interactive experience without spending too much time on frontend development.
Ease of Use: Gradio’s simplicity allowed for a quick and effective interface.
Real-Time Interaction: Users could upload their images, select scenes, and see the results almost instantly.
As a short way to try our project, you can clone the GitHub repository and follow the guidance to set up everything and run the Gradio interface.
The success of the Interactive Room project showcases how AI technologies can revolutionize the entertainment industry. Here’s how our results can have a real-world impact:
Entertainment: Personalized content is becoming more prevalent. Studios could use this technology to allow fans to interact directly with their favorite characters or movies.
Advertising: Brands could create personalized ads where viewers see themselves in the ad, increasing engagement and connection with the product.
Education: This technology can be used in educational videos, where students can “step into” historical events or scientific experiments, making learning more immersive.
Challenges and Solutions
Throughout the development of the Interactive Room project, we faced several challenges, particularly in managing computational resources:
Training Time: Training the YOLOv10 model for gender classification required substantial computing power. We utilized the Atlas platform, which allowed us to train efficiently while achieving high accuracy.
Solution: By leveraging the high GPU resources available through Atlas.ai, we were able to reduce training time significantly and optimize performance.
GPU Limitations for Face Swapping and Voice Conversion: Although voice synthesis doesn’t require full model retraining like gender classification, both the deepfake face-swapping and voice synthesis processes still demanded significant GPU resources. Running these operations efficiently was essential.
Solution: Utilizing the high GPU capabilities of Atlas enabled us to handle the computational demands of face swapping and voice synthesis effectively, ensuring smooth and real-time processing without resource constraints.
Conclusion
While the Interactive Room project has achieved great results, there is still room for improvement:
Better Realism for Complex Scenes: Although SimSwap performed well in most cases, scenes with complex lighting or rapid motion could be improved with further training and dataset expansion.
Voice Personalization: Future iterations could allow users to further personalize their synthesized voice with more nuanced tone control or emotional expression.
The Interactive Roomproject showcases the integration of three advanced technologies: gender classification, deepfake face swapping, and voice synthesis. By employing YOLOv10 for gender detection, SimSwap for face swapping, and Coqui xTTS for voice conversion, we were able to create a system that allows users to step into their favorite movie or TV scenes.
Through this project, we learned to navigate the challenges of training deep learning models within resource constraints, optimizing the pipeline for efficiency without sacrificing quality. Stay tuned for updates as we add images, demo videos, and further refine the system for a broader audience.