Yes, you didn’t get it wrong. Computers can actually see.
And guess what!
Not only can they see, but they can interpret what they see!
And you know what?!
You have seen this happen yourself! You have seen examples of how computers can see… but you didn’t pay attention to them!
Still not convinced? I’m sure that one example is sufficient to make you see this! Suppose you went on a trip with your friends, took photos, and uploaded them to Facebook, then suddenly, Facebook starts suggesting who you should tag with your photos!

There you go! How can you explain this? Well, it looks like Facebook saw your photo and recognized who was with you on your trip, and accordingly, suggested who you should tag to save you the trouble and effort of tagging people individually. So, logically speaking, Facebook was able to see your images and interpret what’s inside of them.
Fair enough! But just out of curiosity: how does Facebook do this?!
Ok, just so you know, it’s not only Facebook that does this. In fact, a lot of computer programs are able to interpret images — even if their purposes are a bit different than Facebook’s. This is where we start talking about what we call Computer Vision!
In simple terms, Computer Vision is a field that helps computers interpret what’s inside an image and make sense out of it. In order to do this, we mostly rely on Artificial Intelligence techniques, and more specifically, on what we call Convolutional Neural Networks (CNN), which are neural networks specifically designed to extract information from images. Through the rest of the blog, we will be answering the following 3 questions:
- What is an image for a computer?
- How can a computer interpret images?
- How can CNNs extract information from images in order to do this interpretation?
But … First things first!
What is an image for a computer in the first place?
It is true that computers can interpret images as we do, but computers don’t see images exactly as we do!
1. Binary Images
In binary images, as the name suggests, we have 2 colors only: Black and White. That’s what we see. But for the computer, the black color is represented by a 0, and the white color is represented by a 1.

2. Grayscale Images
Grayscale images are images that contain different gray colors. As you know, life is not always in black and white: some things can be in between, and grayscale images are a way to represent these colors that exist in between. In a grayscale image, the value of each pixel can be between 0 and 255 where 0 represents the black color and 255 represents the white color. Values in between represent different levels of the gray color.
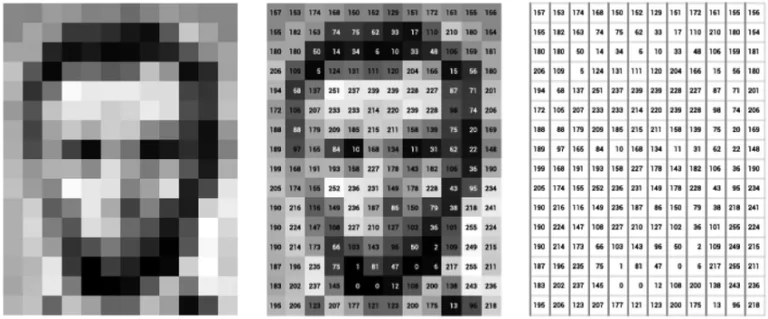
3. Color Images
Finally, we have the images that we mostly see during our everyday life, the color images. But how can we represent their colors? Well, to understand the representation, you should know that any color that we see is just a combination of the 3 colors: Red, Green, and Blue with different intensities. So, to represent any color, we need a specific amount of Red, a specific amount of Green, and a specific amount of Blue. The amount of Red can be represented by a number between 0 and 255 where 0 represents no Red at all, and 255 represents the maximum amount of Red. The same thing applies to Blue and Green. This is why, for a computer, each pixel is represented by 3 values, and each of them is between 0 and 255 as you can see in the figure. The first value represents the amount of Red, the second value represents the amount of Green, and the third value represents the amount of Blue.
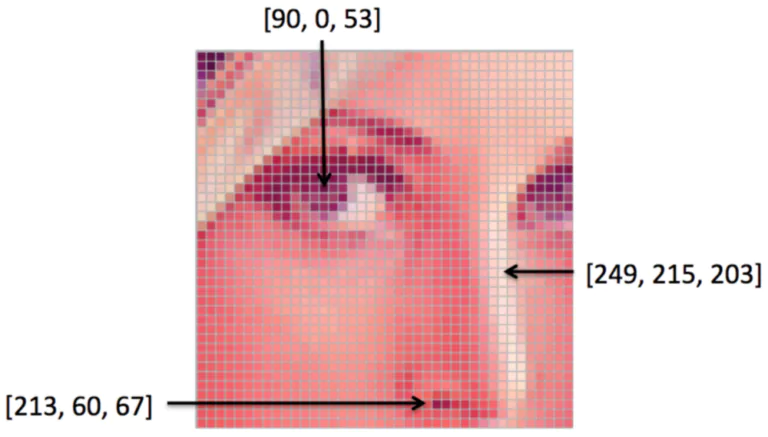
Now that you know that an image for a computer is just a bunch of numbers, the question that you are asking yourselves is …
What can a computer do with these numbers?
As discussed previously, Computer Vision is a field that focuses on interpreting images and extracting information out of them. Now we will discuss what are the tasks that we mostly achieve when using Computer Vision.
1. Image Classification
The goal of image classification is to assign an image to a particular class. Image Classification is useful for many applications. One of them is Medical diagnosis where we get to classify whether a patient has a particular disease out of one of his medical images. Chest X-Rays for instance can help us diagnose diseases like pneumonia, COVID-19, and many others.
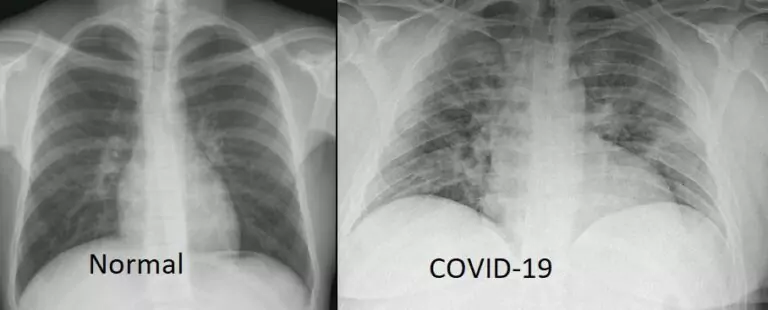
2. Object Detection
The goal of object detection is not only to categorize an image but to locate objects inside of that image. So what we need here is to detect objects within the image and know their exact location. This location is defined by what we call a bounding box, which is just a rectangle that surrounds the object we are looking for. Many applications use Object Detection techniques, and the most popular of them are self-driving cars that have to identify all the objects and their locations in order to ensure a smooth drive and avoid any accidents
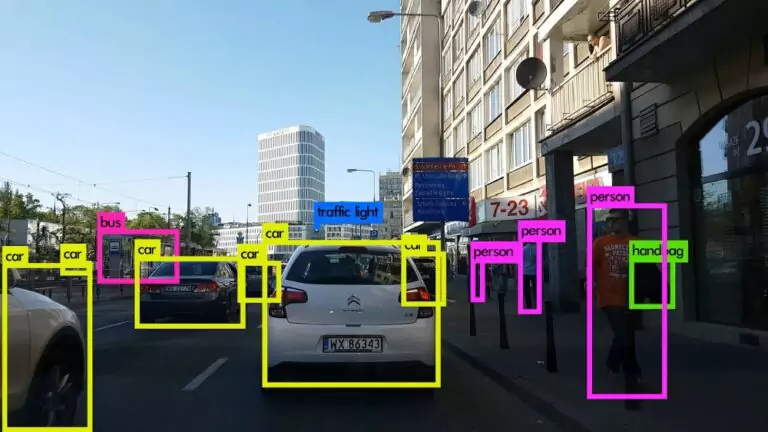
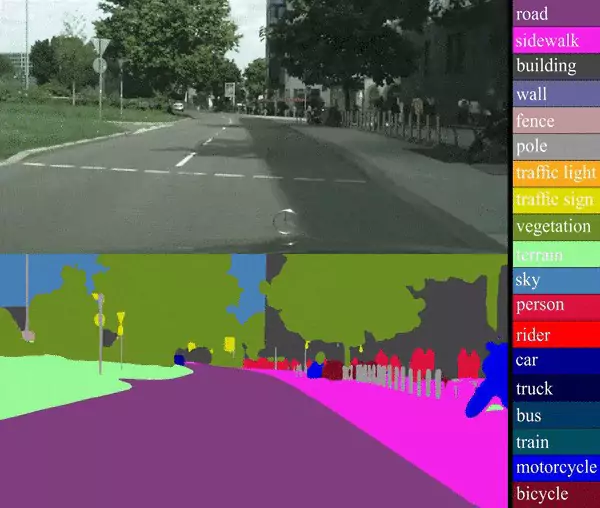
3. Semantic Segmentation
The goal of semantic segmentation is also to search for individual objects within an image. But instead of locating them with a bounding box, in image segmentation, each pixel is gonna be classified according to the content that it holds, and according to the class that we obtain, we know each pixel belongs to which object. The image below clarifies this furthermore.
Great outcomes, but how can they be achieved?
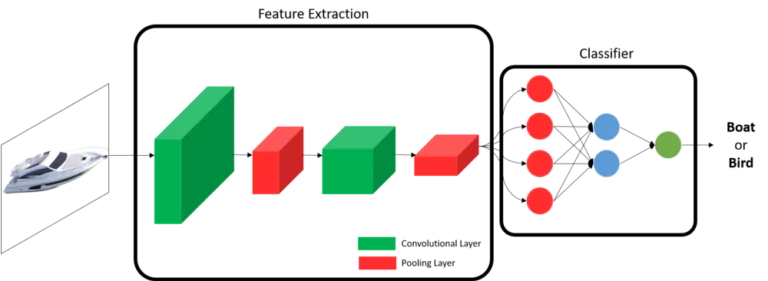
Excellent question! And you have the full right of asking it! To simplify things, let’s say we want to build a model that can classify images.
In order for an image to be classified, there is like a tunnel that it should pass through. This tunnel is mainly composed of 2 parts: the first part is supposed to extract features from the image, and the second part is supposed to do the actual classification based on the extracted features. These facts can be highlighted in the figure below.

1. Before understanding convolutional layers, let’s understand convolutions!
In simple terms, convolution is a mathematical operation that helps extract specific patterns from an input image going from simple lines or edges to complex things like eyes and faces. In order to do the convolution, we need to have what we call a “kernel” that specifies, in one way or another, the kind of information that we are willing to extract from the image. This kernel is going to slide over the image (input feature map) as you can see in the image below, and while sliding, it is going to be extracting information and saving it to the output feature map.
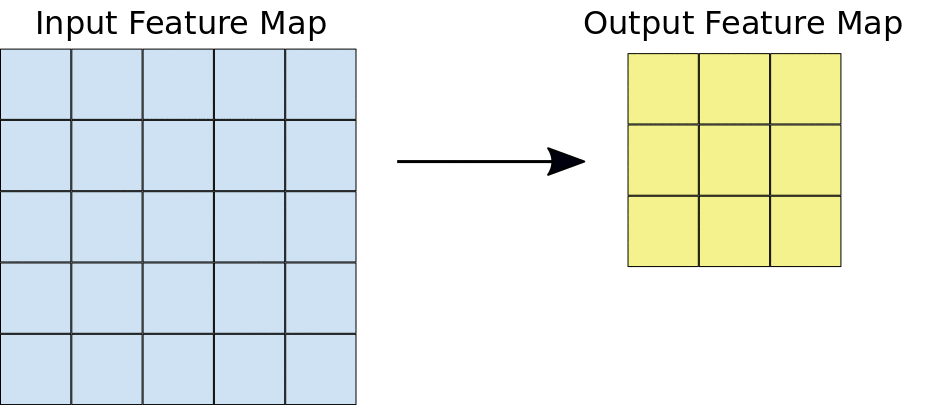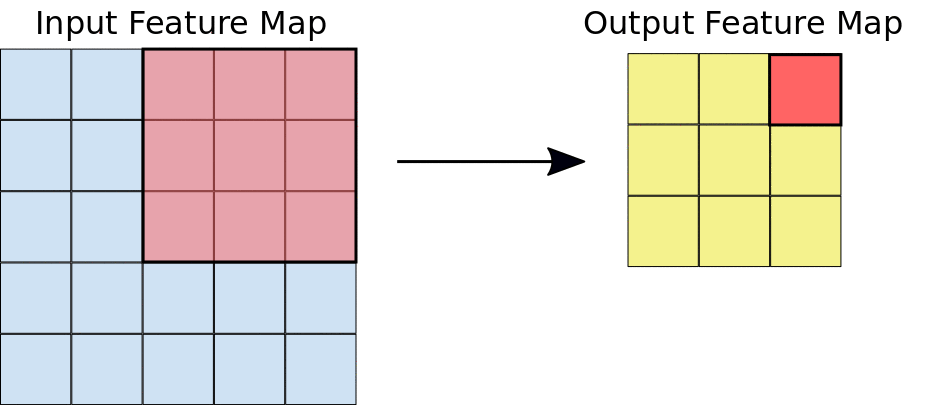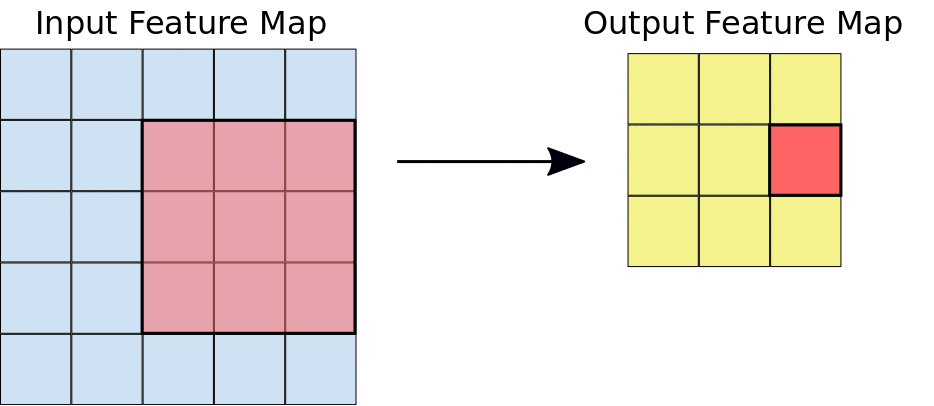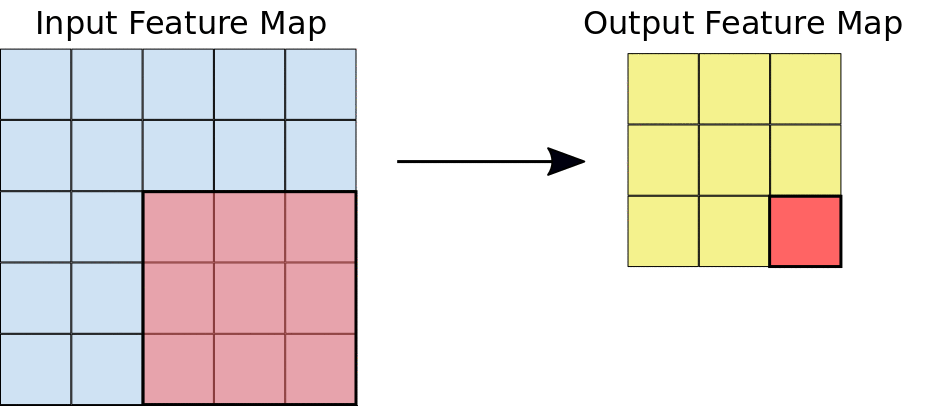
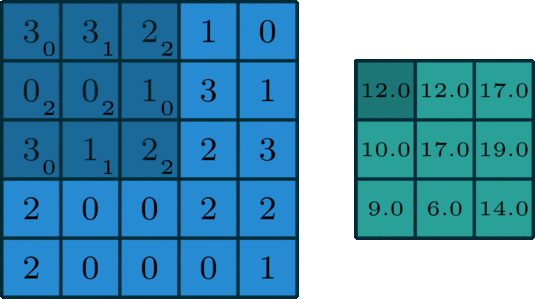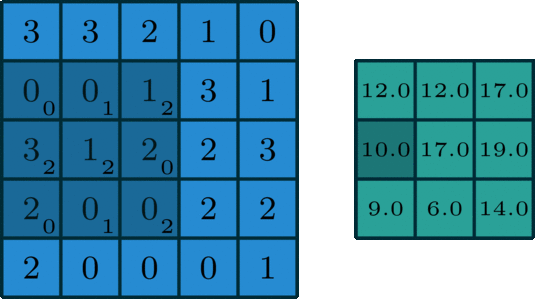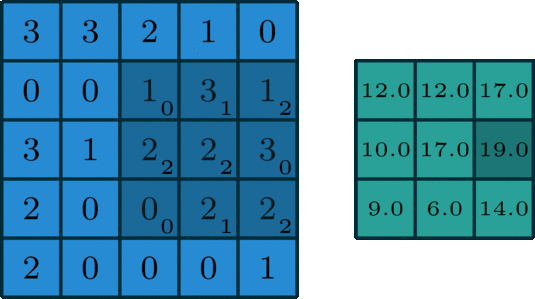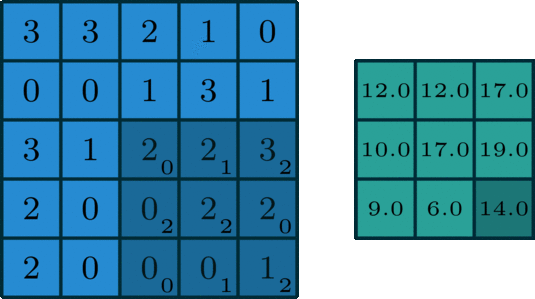
Now, imagine that you change the values of the kernel, and you pass it over the same image. What would happen to the output?! It would definitely change because you would be extracting a different kind of information.
2. Going from a simple convolution to a convolutional layer
A convolutional layer is the essence of a CNN. This convolutional layer is supposed to apply multiple convolutions to the input that it receives. Each of these convolutions is supposed to extract particular information according to the kernel values for each of them. But how do we know what these values are? Well, these values are LEARNED by the network. In fact, during the training process, the network is gonna be learning what are the optimal kernel values that are supposed to give us accurate predictions. In other words, the network will be learning what are the features that we are looking to extract from the input image in order to base our predictions on.
3. Now we got information … Let’s compress it with a pooling layer
A pooling layer is a layer that compresses the information we get from our convolutional layer. It is like a filter applied to specific regions of the output feature map. This filter should have a specific size. Let’s say the size is a 2 by 2. What you do in this case is that you divide your image into blocks of that size (2×2 in our case), and then, you apply the pooling operation on each of these blocks. The pooling operation is also mathematical and can be of 2 kinds: Max Pooling, or Average Pooling. When we talk about Max Pooling, we take the maximum value of a block, and when we talk about Average Pooling, we take the average value of a block. The image below can help you understand the process even more on a simple example.
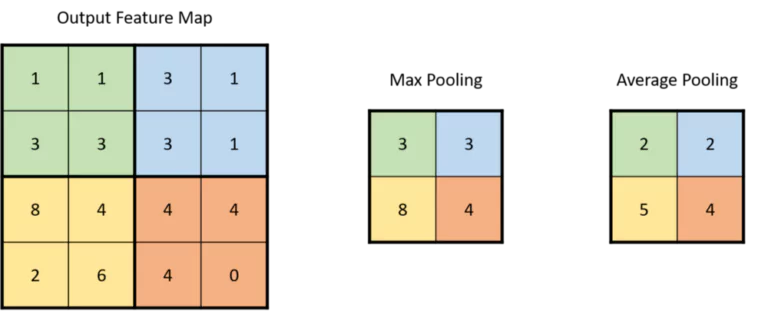
4. Putting Everything together … CNN
Now that you know the building blocks of a CNN, let’s see what a typical CNN looks like. A typical CNN’s goal is to extract the maximum amount of features from an image, but we need these features to be relevant. For this reason, in a CNN, we alternate between convolutional layers and pooling layers. The convolutional layer will extract information from an image and the pooling layer will compress this information. Then, this compressed information is fed to another convolutional layer that will extract more information, and then the output passes to another pooling layer for compression, and so on. We keep doing this until we reach a limited number of features that we choose. These features will be characterizing an image, so we can feed them to a classifier in order to perform image classification.
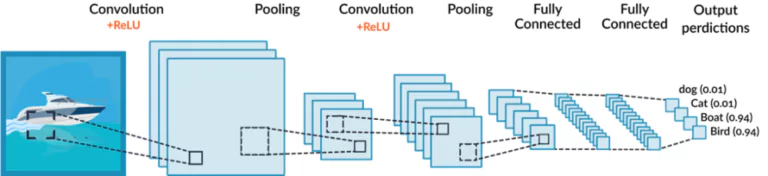
Et Voilà!
As you have seen, Convolutional Neural Networks are very much essential in order to extract features from images. In this blog, you have learned about what is computer vision, what tasks are usually done in it, and how Convolutional Neural Networks help in achieving these tasks by extracting features from images.
Want to know how to write a code that can make use of CNNs to perform image classification?
Stay tuned for the next blog post!