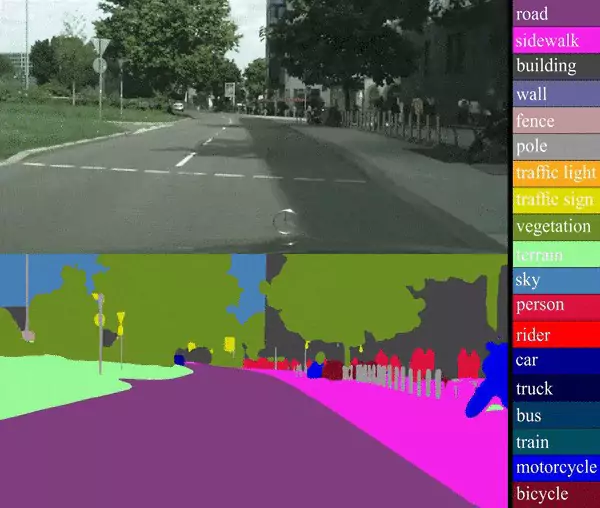
Ok, so what I mean is that the conclusions that we come out with when looking at images are similar to the conclusions that computers will derive while looking at them, although we are seeing kind of different things! So, when we look at an image we see colors, shapes, objects, etc. And based on these, we interpret it. So, if we look at the image of a person, and we want to tell whether this person is a male or a female, we look for specific things like hair, beard, etc. Although a computer might come up with the same conclusion, do you think that the computer saw the same thing in order to interpret? So, do you think that the computer saw the hair or the beard explicitly as we did?
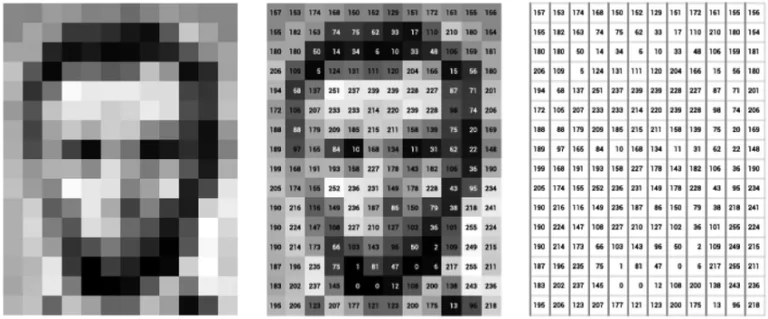
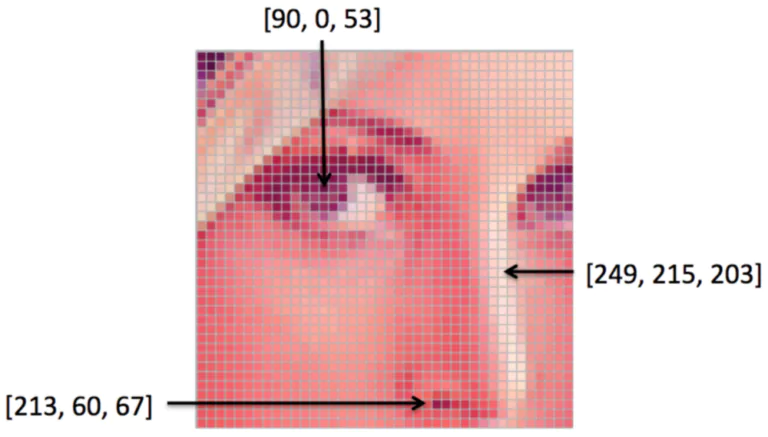
The short answer to this is NO, it didn’t. At least, not explicitly. In fact, a computer sees the image as a matrix of pixels! A pixel is the smallest entity of an image and is characterized by some values that represent the intensity of the colors in that pixel. The computer sees only those! But for us, it is these values that make us see what we see! So, in simple terms, an image for a computer is just a bunch of numbers placed in a matrix, and the computer tries to interpret an image based on these numbers only.
It’s fascinating, isn’t it? Let us see what are these values exactly and how can they represent different colors in each kind of image.
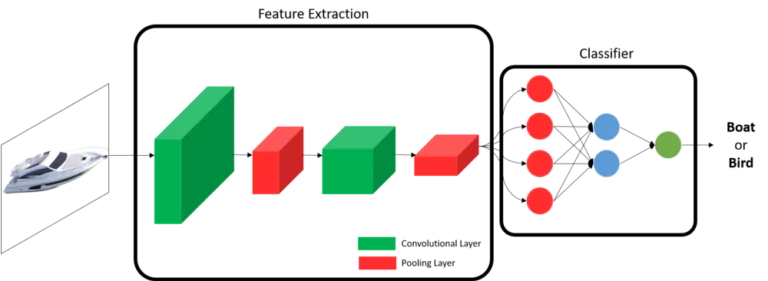
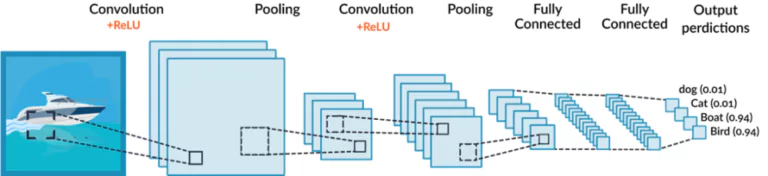
Now how can we do the automatic feature extraction from images? This is where we use what we call “Convolutional Neural Networks” or CNNs for short. CNNs are very much useful when dealing with images. Just like normal neural networks, a CNN is made of multiple layers. The difference is that there are different kinds of layers that can be involved in a CNN which mainly are the convolutional layers and the pooling layers..
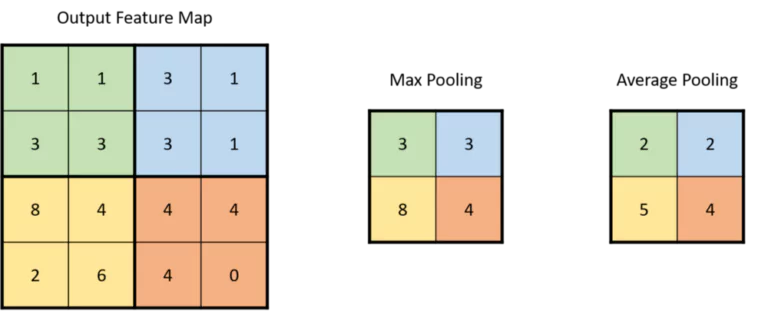
In simple terms, a convolutional layer will extract information, and a pooling layer will compress this information. Now we will understand how each of these layers is supposed to do its job.
Take a minute to look at the above image carefully before continuing!
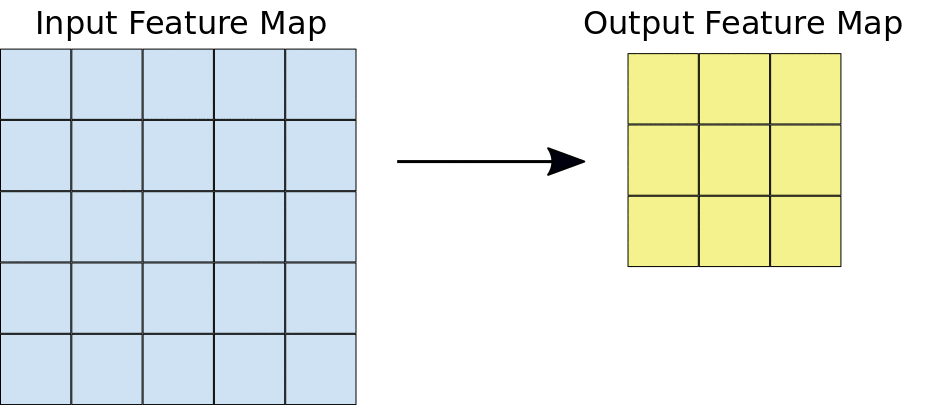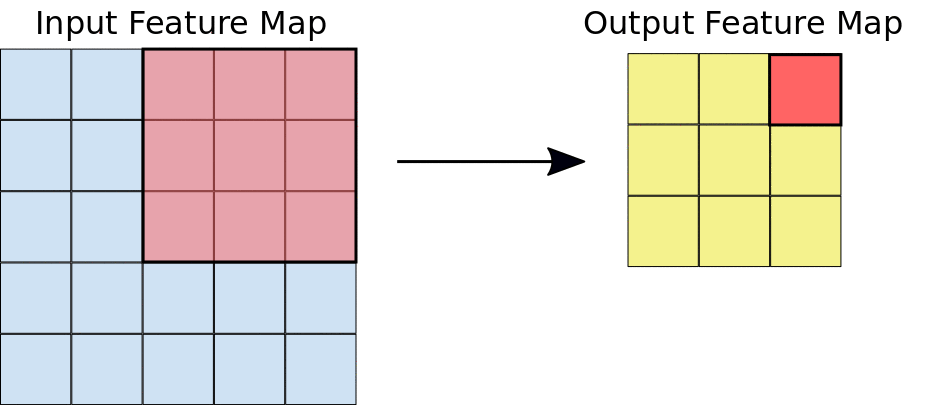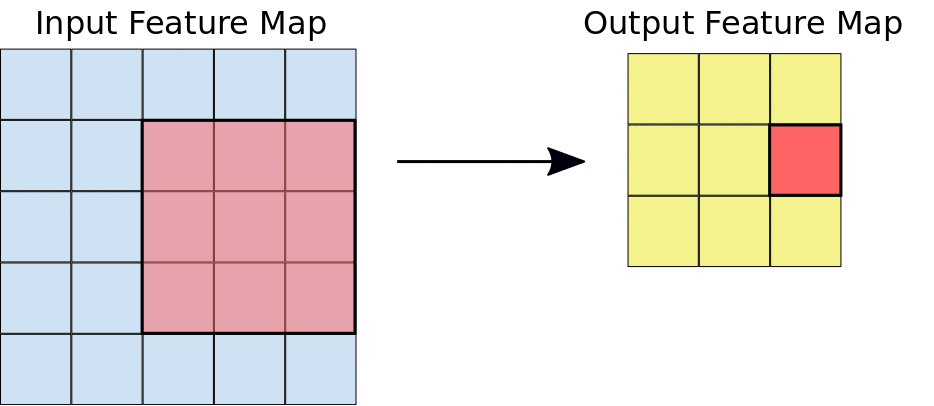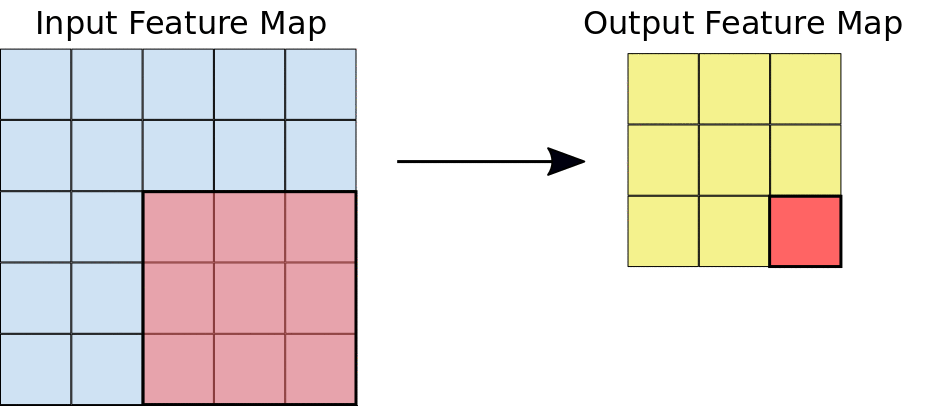
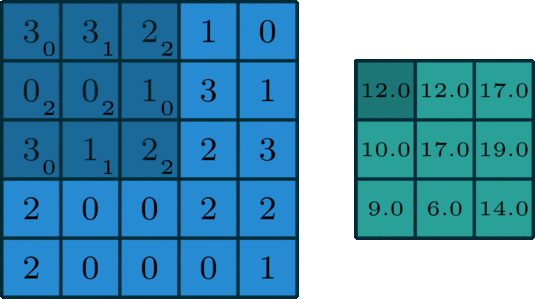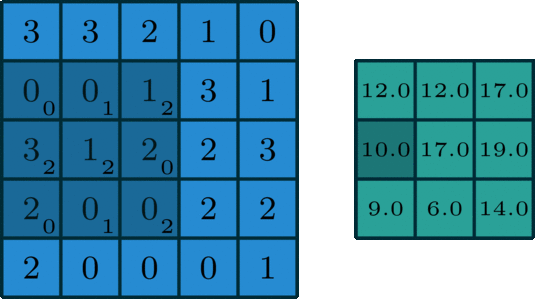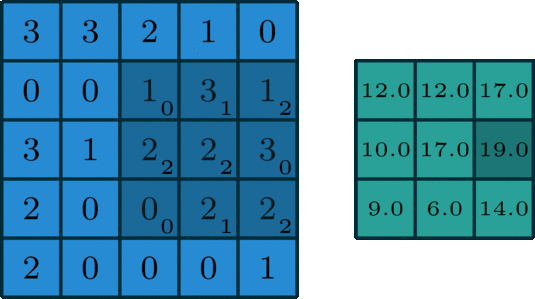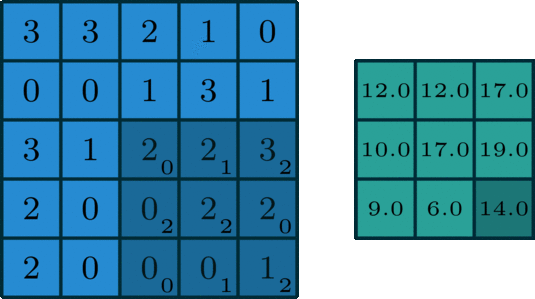
Just to give you intuition, the process that happens here is purely mathematical where you would be dotting matrices, and depending on the kernel that you choose, you would obtain a different output. If you look at the image below, you will get a better understanding of how things are done mathematically. The kernel used in this example is a 3 by 3 matrix represented as follows: kernel = [0 1 2; 2 2 0; 0 1 2].
When the kernel is in a particular position, you need to do the dot product between the kernel values and the image values under this kernel, and you put the result in the output feature map. You keep sliding the window and doing the above operation until your kernel passes over all pixels in the image.