Methodology
Step 1: Speech Recognition
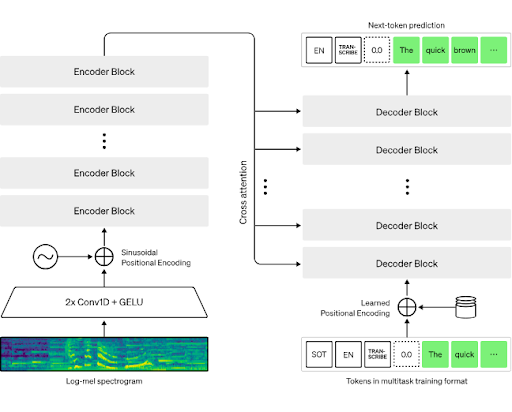
To enable real-time language understanding, we started with Wav2Vec2 which is a self-supervised speech recognition model developed by Meta AI. It is able to learn speech representations directly from raw audio. Wav2Vec2 achieved a word error rate (WER) of 25.81%. To enhance accuracy across Arabic, English, and French, we upgraded to the Whisper model, which lowered the WER to 15.1%. Whisper’s multilingual capabilities and automatic language detection streamlined the user experience by eliminating the need for manual language selection.
Step 2: Text Generation
For text generation, we initially used LLaMA 3.1, fine-tuning it with datasets such as Arabica_QA and TyDi QA, as well as custom datasets related to Lebanese culture. When LLaMA 3.2 launched, we transitioned to this updated model for better native Arabic support. Our custom datasets ensured culturally accurate responses, especially when handling Arabic input, while retrieval-augmented generation (RAG) added depth to answers by pulling in relevant information.
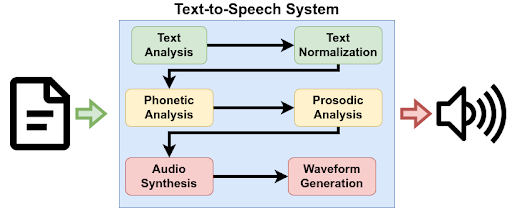
Step 3: Text-to-Speech Synthesis
After testing several models, we chose Google Text-to-Speech (gTTS) for its fast, resource-efficient performance. This allowed us to meet real-time demands, an essential component for the fluid, interactive experience with our avatar. Our custom avatar, named LIA (Lebanese Information Assistant), uses a female voice from gTTS to create a friendly, welcoming persona.
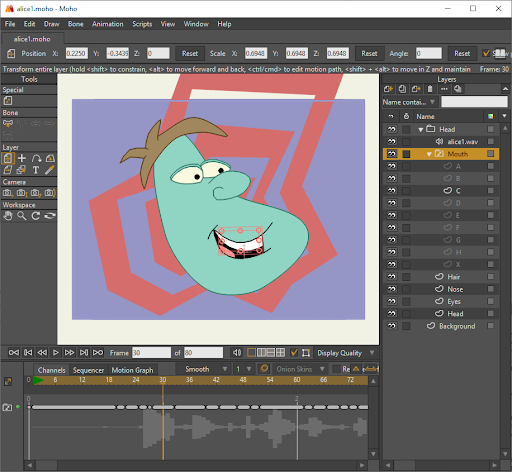
Step 4: Lip Synchronization
We integrated Rhubarb to synchronize lip movements with speech. Rhubarb translates audio into phonemes, mapping them to specific mouth shapes (visemes) for realistic, real-time lip syncing. By pairing these animations with LIA’s spoken output, we created an immersive, human-like interaction for users.
Results and Findings
Our final implementation met key project goals in real-time multilingual interaction, delivering marked improvements across speech recognition, text generation, and lip synchronization.