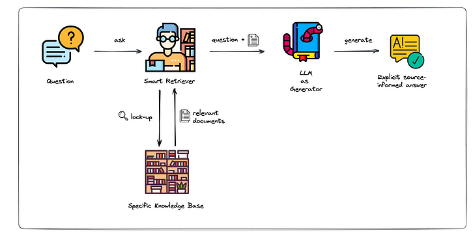
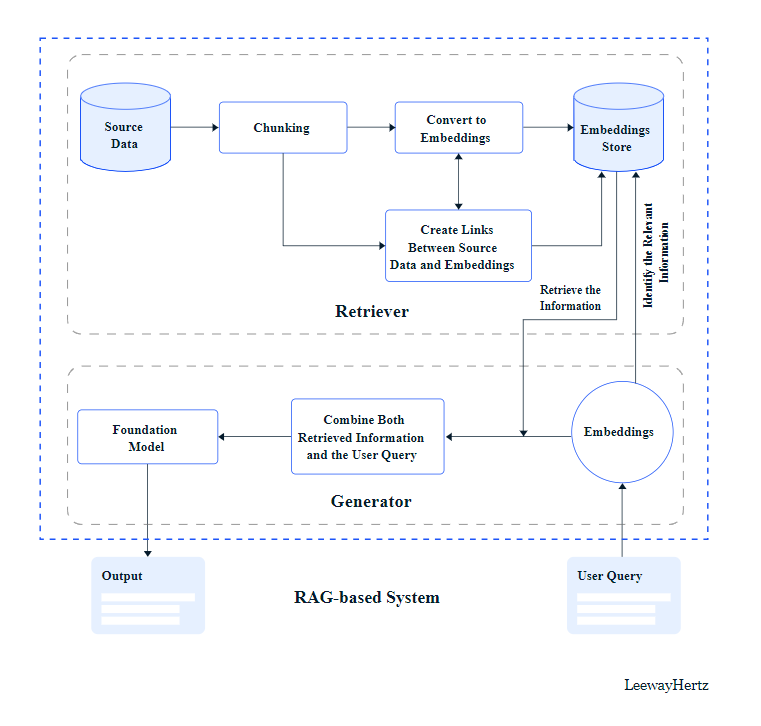
Upon receiving your query, a complex process, obviously😄, starts at the foundation of our RAG-based system where the query is first segmented into digestible pieces that are then encoded into rich embeddings (a fancy way to say numerical vectors). This step is crucial so that the machine can search for semantically similar items based on the numerical representation of the stored data.
I can only read numbers
In the heart of the operation, the Retriever acts with precision, pinpointing the embeddings that align with your query. This game of matching is key to sourcing the most relevant information.
With the intelligence gathered, the Generator takes over. It integrates the context from the Retriever with your initial inquiry, crafting a precise response. In other words, the system brings together the identified data chunks and your original prompt, laying the groundwork for the foundation model, like GPT (Generative Pretrained Transformer), to step in.
The outcome is a seamless blend of retrieved knowledge and generative expertise, culminating in an output that is both insightful and relevant to your query. This is the essence of RAG: a system where complexity meets clarity, transforming how we interact with and benefit from AI in our quest for information.
But Wait, There’s a Catch!
Before you start thinking RAG models are the solution to all life’s problems, remember – they’re only as good as the data they have access to.
🚮 in, 🚮 out, as they say. You know what I’m talking about, right?