Tools and Techniques
Data Processing
Random Oversampling: Addressed class imbalance by increasing the minority class instances, ensuring the model learned patterns effectively. We used SMOTE technique (Synthetic Minority Oversampling Technique) to have AI generated synthetic data to solve this problem.
Label Encoding: Converted categorical features like Sex and Periodontal Disease into numerical formats suitable for machine learning algorithms. Some of them were mapped, for example Male: 0 and Female: 1 while others were done by one hot encoding using LabelEncoder.
Machine Learning Models
The model was trained using:
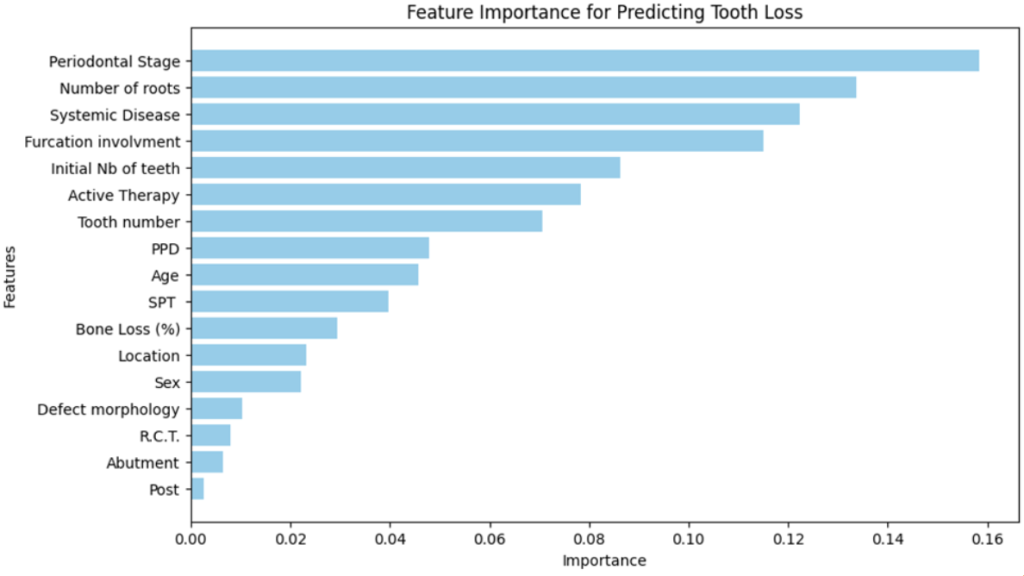
17 Features: including age, Sex, Initial No. of Teeth, Tooth number, PPD, Active Therapy and others.
Target: Binary classification of Tooth Loss (Yes/No).
Deployment Framework
Using Gradio, the project offers an interactive interface for users to input patient details, instantly receiving predictions. Gradio bridges the gap between complex machine learning models and user-friendly interfaces.
Methodology
Step 1: Data Cleaning and Preprocessing
The raw dataset included categorical and numerical variables, necessitating extensive preprocessing, some processing included:
Missing values were addressed to maintain dataset integrity.
EDA (Exploratory Data Analysis): Matching values that look different but are the same as “Upper Posterior” and “Posterior Upper”
Standardize some features such as those that have different uppercase letters such as “vertical” and “Vertical”, those values are very sensitive to the model and may consider them different, so they need to be addressed.
Categorical features were encoded into numerical using different methods such as mapping and one-hot encoding.
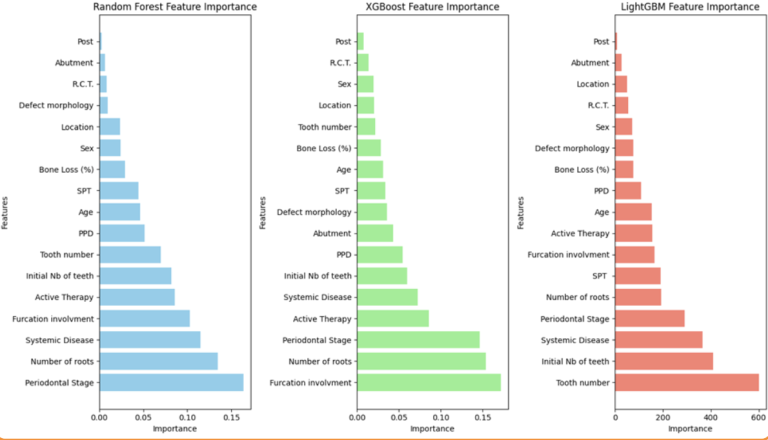
Checking the correlation between each feature and the target column “Tooth loss” by relying on different metrics, for example. The categorical data were checked using Chi-square value; after computing the Chi-square value, it is compared to a Chi-square distribution table using the degrees of freedom to determine the p-value. If the p-value is below a certain threshold (e.g., 0.05), the result is considered statistically significant. The following image is one of the results, showing the distribution of tooth loss along the bone loss %.